在这个课程的前期李宏毅老师主要在讲ML算法的理论依据,我感觉听起来比较抽象,本周主要学习了以下几项内容:
1.传统的Linear Regression回归分析方法,参数的多少和模型的复杂程度对model结果的影响,以及通过正则化来解决过拟合问题。
2.Regression模型的误差来自bias还是variance,如果是前者就是欠拟合,后者就是过拟合,以及解决这些误差的办法。
3.gradient descent的基本原理,learning rate太大或太小带来的影响,调整learning rate的adagrad算法实现,为什么要Feature Scaling以及如何做,gradient descent的理论基础:用一阶Taylor展开拟合,因此要求learning rate足够小。
4.分类问题和回归问题模型上的区别,Generative model的流程:需要事先对模型进行假设,如符合高斯分布等等,然后根据极大似然估计评价该分布的参数的好坏。
5.Logistic Regression的步骤,交叉熵的原理和含义,Logistic Regression和Linear Regression的区别,为何Logistic Regression的loss function要采用交叉熵而不是采用方差,Discriminative model 和 Generative model的区别与优劣:Discriminative model不对模型预先进行假设,十分依赖data, 比较适合图像识别等领域;Generative model对data没有前者那么依赖,但需要对模型进行部分假设,例如语音识别系统等领域,对声音的识别还依赖于某句话被说出来的几率。
6.由Logistic Regression到神经网络的过渡,再到deep learning,这块比较具体,很好理解。
7.反向传播的原理,forward pass比较容易,backward pass,建立一个与原来相反的神经网络,每一个反向的neuron的输入就是loss对后面一层layer的z的偏微分,输出就是loss对这个neuron的z的偏微分(这块有点难理解,我还没理解透😌)
在完成对机器学习基础内容的学习后,我进行了CNN相关内容的学习,对CNN的工作流程和原理进行了一些了解:
1.对CNN工作原理的初步了解,从最直观的角度考虑,它的工作原理就是对一张图片信息的侦测,不同于普通的神经网络,CNN中的每一个Filter其实就等同于是Fully connected layer里的一个neuron,李宏毅老师的理解比较直观,他认为在CNN的工作过程就是对图片关键信息的抽取,例如识别鸟的照片就有对鸟啄这一图片局部信息提取的过程,而这一过程就是通过一个个Filter实现的:

而每一个Filter就是通过与图片的局部进行内积运算,来实现对图片局部信息的抽取。要注意的是,每一个Filter只需要对图片的一个部分进行运算,每个filter只与图片的部分进行连接,而非一整个图片,可以通过改变从filter到图片局部的连接来实现filter移动的效果,这里李彦宏老师讲的比较清楚

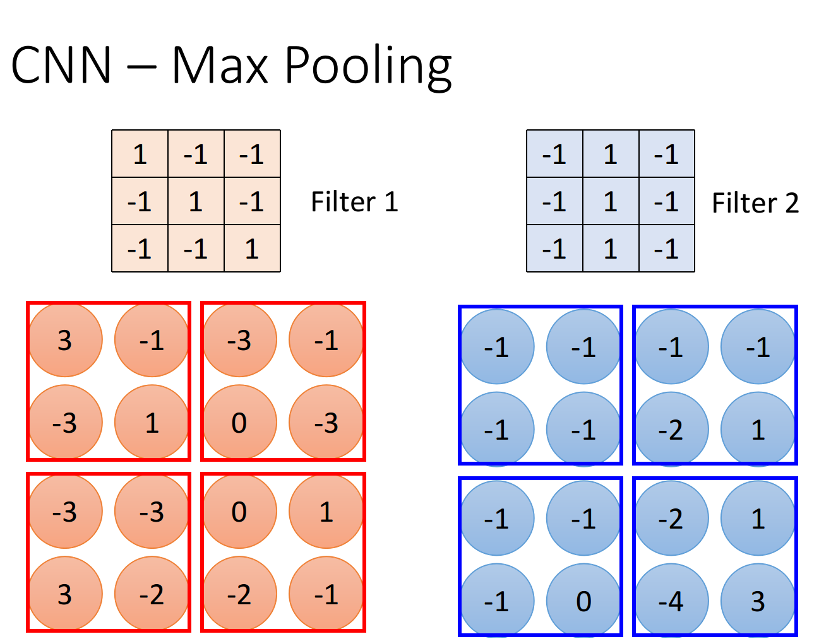
2.上面讲的是卷积的过程,CNN的主要工作分为卷积和池化两步。相较于convolution,max pooling是比较简单的,它就是做subsampling,根据filter 1,我们得到一个4*4的matrix,根据filter 2,你得到另外一个4*4的matrix,接下来,我们要做什么事呢?
我们把output四个分为一组,每一组里面通过选取平均值或最大值的方式,把原来4个value合成一个 value,这件事情相当于在image每相邻的四块区域内都挑出一块来检测,这种subsampling的方式就可以让你的image缩小。
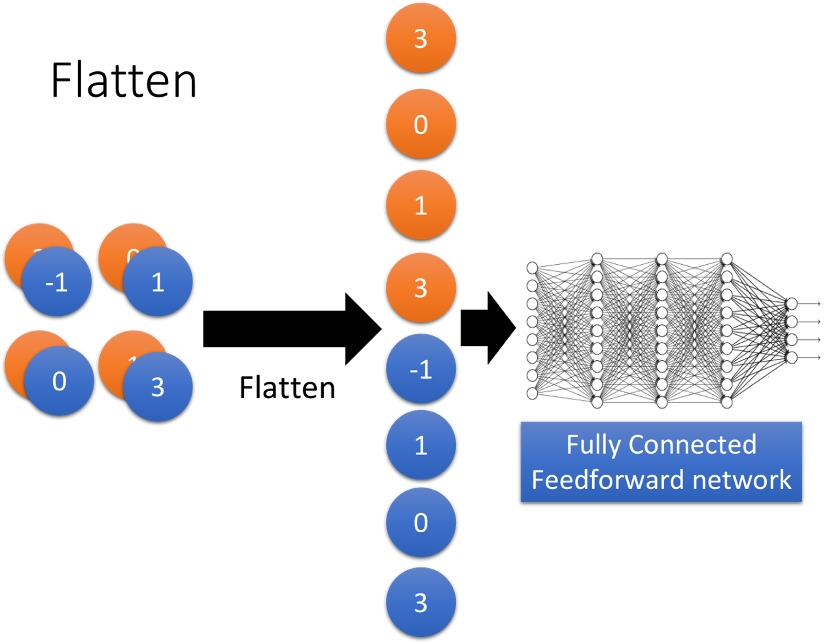
3,做完convolution和max pooling之后,就是FLatten和Fully connected Feedforward network的部分
Flatten的意思是,把左边的feature map拉直,然后把它丢进一个Fully connected Feedforward network,然后就结束了,也就是说,我们之前通过CNN提取出了image的feature,它相较于原先一整个image的vetor,少了很大一部分内容,因此需要的参数也大幅度地减少了,但最终,也还是要丢到一个Fully connected的network中去做最后的分类工作。
4.除了CNN的工作原理,李宏毅老师还讲了很多CNN的应用,除了图像处理方面,CNN还可以用在其他很多方面,例如围棋、文字语义分析、语音识别等等。李宏毅老师提出了一个问题能否用CNN解决的三个判断标准:
三个property
- 某些关键性图案/纹路比整个图片/信息小
- 相同的图案/纹路可以出现在不同的地方
- Subsampling不会使得信息的关键/本质发生变化
前两者是CNN中卷积能够生效的关键,而最后一项是池化能够生效的关键。
5.本周还学习了许多在深度学习中可以提高学习效果的内容,主要分为如何在测试集和训练集上获得更好的结果两部分:
在训练集上想要获得好的结果可能要解决梯度消失问题,我们可以通过更换activation function的方法,例如ReLU函数,或者使用maxout自动选择合适的activation function;在训练集上想要获得好的结果也可能需要更好的learning rate的adaptive方法,除了上个星期所学的adagrad,还有很多先进的方法,例如RMSProp,你可以通过修改参数来使最近的gradient作为你lr更新的参考依据而不是过去所有的gradient,或者Momentum方法,可以理解为惯性,在更新时保留上一次gradient的方向的一部分作为下次更新的矢量,甚至结合RMSProp和Momentum,即Adam方法。
想要在测试集上想要获得好的结果,可以采用regularization,即通过调小weight的绝对值使整个function更加平滑的方法,分为L1和L2两种
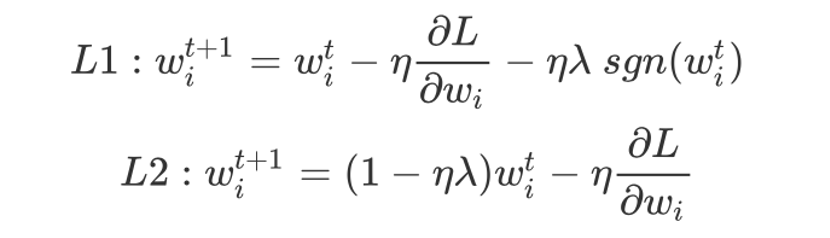
L1和L2,虽然它们同样是让weight参数的绝对值变小,但它们做的事情其实略有不同:
- L1使参数绝对值变小的方式是每次update减掉一个固定的值,其中sgn函数的意思是说,如果w是正数的话,这个function output就是+1,w是负数的话,这个function output就是-1
- L2使参数绝对值变小的方式是每次update乘上一个小于1的固定值
此外,还有一种方法可以提高在testing data上的效果,它就是dropout,可以理解为在训练时丢掉一半的neuron,在testing data时则使用100%的neuron。
6.除了理论的学习,我还进行了pytorch的部分学习,不过搭环境花掉了部分时间,特别是在conda环境中安装pytorch,尝试了许多方法,最后使用梯子才成功。此外python虽然很好用,但是我觉得还是要花时间专门去学习一下啊,python对类型的弱化真的让我有点不适应。